Conversational Kotlin: A Look at the Benefits of Readable Code

In the latest blog from Engineering@Tenable, we explore how the goal of readable code can help engineering teams minimize errors and expedite software updates.
It’s probably a safe assumption that most software engineers, on multiple occasions, have opened an old code base and had to divine the intentions of the author. This can lead to much head-scratching (and, sometimes, mumbled expletives). But it doesn’t have to be that way, and a strong focus on code readability is the key.
Of all the qualities code can be judged on, readability may be the most important and the hardest to automate because evaluation is at least partially subjective. Consider the idea of pseudocode, an informal description of algorithmic rules that more closely resemble English than any particular programming language. It can be used to quickly discuss ideas and designs without needing specific syntax. Here’s an example for a simple algorithm to calculate the average test score for a class:
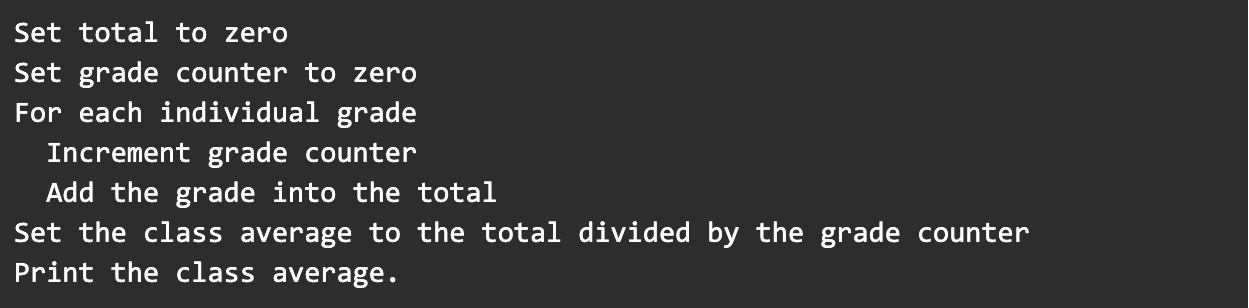
Across all levels of technical skill, pseudocode is a generally well-understood, common language for describing how a problem can be solved. How closely actual code resembles pseudocode is one way to measure readability. Obviously, specific language syntax will impose some limits, or expose some freedoms.
For those using the functional programming paradigm, the concept of point-free style (aka tacit programming) may be familiar. You might see some JavaScript like this in a video game store application:
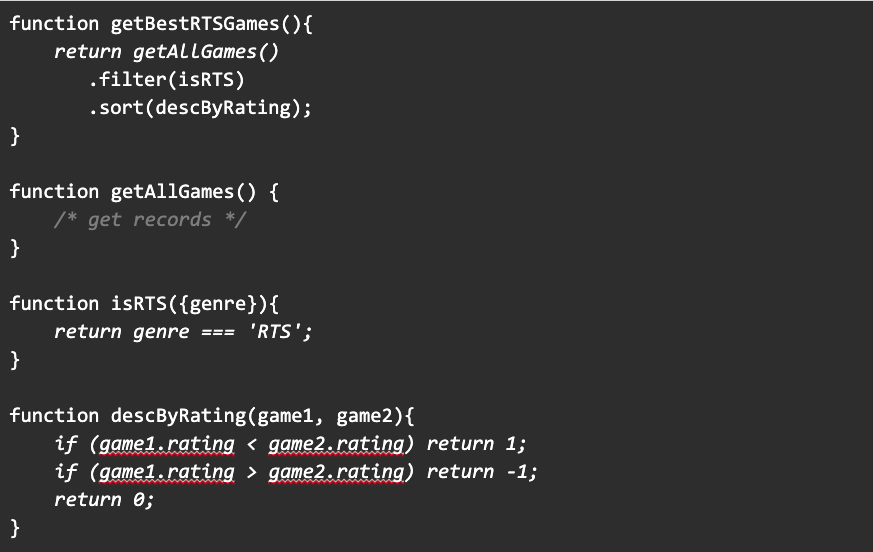
Composing functions without explicit arguments, so that the output of one is the implicit input of the next, can result in pleasantly readable code. In this article, I’d like to show an example of how Kotlin’s extension functions can facilitate the same improved readability.
We use Kotlin extensively at Tenable. Much of our product runs in the Java virtual machine (JVM), so interoperability with Java and Groovy were important. Kotlin is a more modern and concise language with numerous features at the language and compiler levels that make it preferable to its predecessors, yet still similar enough to Java that learning it is easy.
A Real-World Example: Normalizing Vulnerability Scan Results
Within Tenable.io, we do a lot of stream processing. The power of the tools we build for our customers comes directly from the data flowing through those streams. For the sake of this example, I will use the stream within Tenable.io which processes results from vulnerability scanners. A rough approximation of this workflow looks something like this:
Each scan result contains information about the scan host which was discernible by the sensor, as shown here in an example from our hypothetical customer “Stark Industries”:
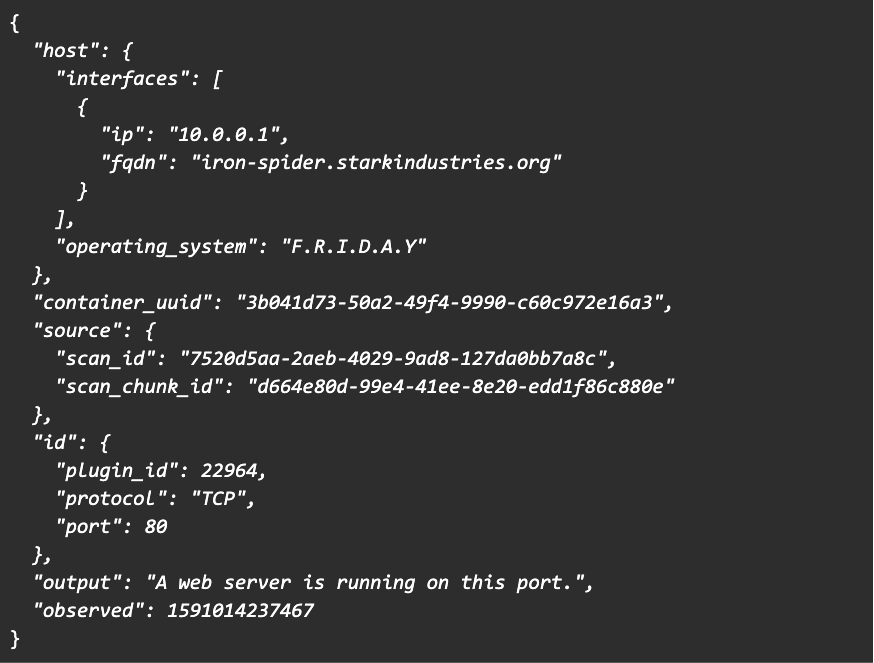
The goal of the scan normalization application consuming the stream of scan results is twofold. First, it provides the required data to downstream processors which build specialized data stores for APIs, dashboards and reports. Second, it limits resource demands by reducing the volume of data sent through the “pipeline.” To achieve those goals, the application needs to transform and aggregate the data in the input stream of scan results, then output a second stream of normalized scan host findings.
For our application, there are a few relatively simple steps. As each item in the stream is processed, it is mapped from the data model of the input stream to the data model of the output stream. Whenever consecutive records appear in the stream for the same plugin, on the same port of the same scan host, they are grouped together. For each group of records (most of which are groups of one), a single record is compiled which contains the concatenated output of all the individual records in the group. If the final size of the output text is larger than 1MB, the output is stored externally, and the final item has its output value replaced with the URI of the stored resource.
Pseudocoding a simple algorithm design for the application might look something like this:

Improving Code Readability With Kotlin Extensions
At Tenable, we often use reactive programming. Continuing with the real-world example, you will see use of the Flux class, which is basically a streaming collection of records of the templated type. The first pass at implementing this logic without the use of extension functions looked something like this:
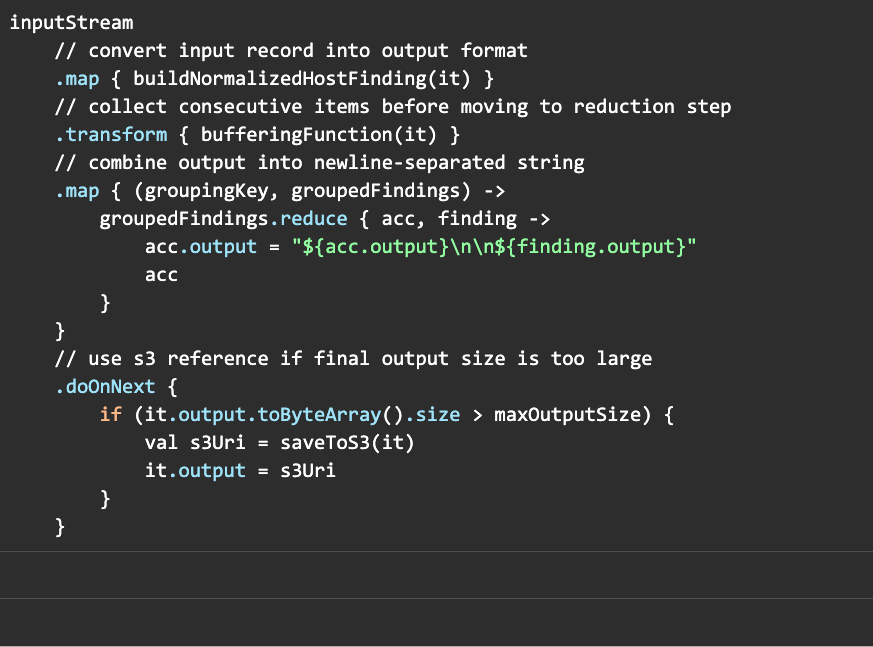
Each function in the chain corresponds to one of the steps in the algorithm. The first step takes a stream of ScanResult records and outputs a stream of NormalizedHostFinding records. The second step buffers the stream and outputs a stream of pairs, where each pair consists of a key (including the common scan host, plugin, and port), and a collection of the NormalizedHostFinding records which have that key. The third step consumes that stream of pairs and again outputs a stream of single NormalizedHostFinding records by concatenating the output of all records in the collection. The last step outputs the same stream it received, sometimes moving the output to an external location before passing through the NormalizedHostFinding record.
The code above is not overly complex, but with the goal of improving readability, it could be refactored to appear more like the high-level pseudocode above. That can be achieved by introducing four extension functions, one for each step’s output stream type. Kotlin extensions are great as they allow you to add methods to a class without having to inherit or use design patterns such as Decorator:
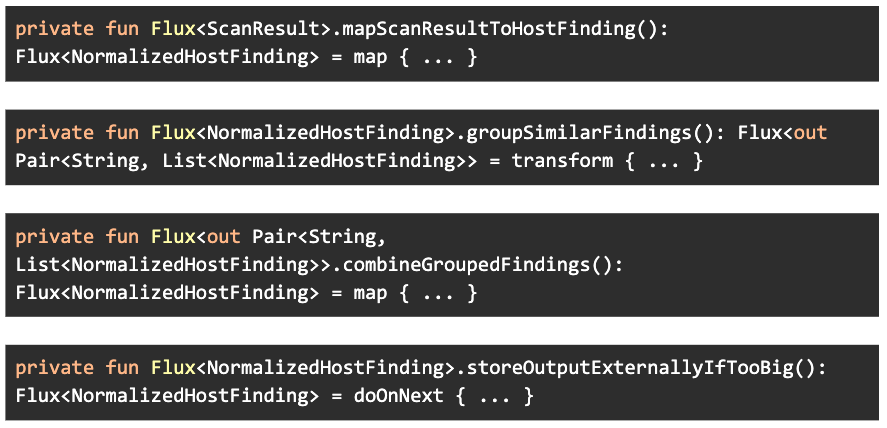
Adding these extensions then allows our main function to be rewritten as:

A noticeable improvement, and with not too much extra effort. In general, using descriptive names for functions instead of lambdas may seem like overkill, but can go a long way.
As I’m sure many can attest, digging into new code can be overwhelming. Sometimes, even our own code can seem foreign after too much time has passed. With readability as a goal instead of an afterthought, we can reduce barriers to productivity and even prevent mistakes due to misunderstandings.
Are you an engineer looking for your next career opportunity? Visit our Tenable Careers page to see which open engineering positions might be right for you.
Learn more




Tenable One
Request a demo
The world’s leading AI-powered exposure management platform.
Thank You
Thank you for your interest in Tenable One.
A representative will be in touch soon.
Form ID: 7469
Form Name: one-eval
Form Class: c-form form-panel__global-form c-form--mkto js-mkto-no-css js-form-hanging-label c-form--hide-comments
Form Wrapper ID: one-eval-form-wrapper
Confirmation Class: one-eval-confirmform-modal
Simulate Success